Scrapyフレームワーク
Scrapy

Scrapy at a glance
Scrapy is an application framework for crawling web sites and extracting structured data which can be used for a wide range of useful applications, like data mining, information processing or historical archival.
ScrapyはWebサイトのクロールとスクレイピングを行うアプリケーションフレームワーク。
Built-in support for selecting and extracting data from HTML/XML sources using extended CSS selectors and XPath expressions, with helper methods to extract using regular expressions.
CSSセレクターやXPathを使ってHTML/XMLソースから抽出することができる。
An interactive shell console (IPython aware) for trying out the CSS and XPath expressions to scrape data, very useful when writing or debugging your spiders.
CSSセレクターやXPathを試すためのインタラクティブシェルが用意されている。
Built-in support for generating feed exports in multiple formats (JSON, CSV, XML) and storing them in multiple backends (FTP, S3, local filesystem)
複数のデータフォーマットでエクスポートし、複数のバックエンドへ保存することができる。
Robust encoding support and auto-detection, for dealing with foreign, non-standard and broken encoding declarations.
堅牢なEncodingサポートと自動検出。
Strong extensibility support, allowing you to plug in your own functionality using signals and a well-defined API (middlewares, extensions, and pipelines).
強力な拡張性。
Wide range of built-in extensions and middlewares for handling:
- cookies and session handling
- HTTP features like compression, authentication, caching
- user-agent spoofing
- robots.txt
- crawl depth restriction
- and more
- Cookieとセッションハンドリング
- 圧縮、認証、キャッシングなどのHTTP機能
- User-Agentの偽装
- robots.txt対応
- クロールの階層制限
A Telnet console for hooking into a Python console running inside your Scrapy process, to introspect and debug your crawler
Scrapy内で実行されているPythoneコンソールをフックするTelnetコンソール。
Plus other goodies like reusable spiders to crawl sites from Sitemaps and XML/CSV feeds, a media pipeline for automatically downloading images (or any other media) associated with the scraped items, a caching DNS resolver, and much more!
SitemapやXML/CSVフィードからサイトをクロールするためのSpider、スクレイピングされたアイテムに関連付けられた画像等を自動的にダウンロードするためのメディアパイプライン、キャッシングDNSリゾルバーなど。
Architecture overview
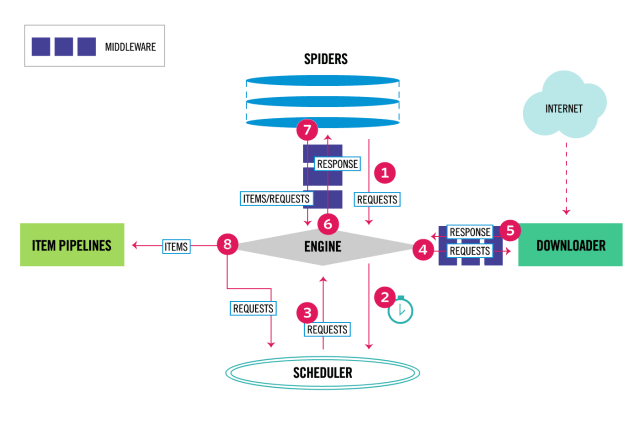
The data flow in Scrapy is controlled by the execution engine, and goes like this:
- The Engine gets the initial Requests to crawl from the Spider.
- The Engine schedules the Requests in the Scheduler and asks for the next Requests to crawl.
- The Scheduler returns the next Requests to the Engine.
- The Engine sends the Requests to the Downloader, passing through the Downloader Middlewares (see process_request()).
- Once the page finishes downloading the Downloader generates a Response (with that page) and sends it to the Engine, passing through the Downloader Middlewares (see process_response()).
- The Engine receives the Response from the Downloader and sends it to the Spider for processing, passing through the Spider Middleware (see process_spider_input()).
- The Spider processes the Response and returns scraped items and new Requests (to follow) to the Engine, passing through the Spider Middleware (see process_spider_output()).
- The Engine sends processed items to Item Pipelines, then send processed Requests to the Scheduler and asks for possible next Requests to crawl.
- The process repeats (from step 1) until there are no more requests from the Scheduler.
- Sipderからcrawlに対する初期Requestsを取得
- SchedulerへRequestsをスケジュールし、crawlに対する次のRequestsを要求する
- Schedulerは次のRequestsを返す
- Downloaderに対してDownloader Middlewares経由でRequestsを送る
- Downloaderはページのダウンロードが完了すると、Responseを生成しDownloader Middlewares経由で返す
- DownloaderからResponseを受け取り、Spider Middleware経由でSpiderへ送る
- SpiderはResponseを処理し、スクレイプしたアイテムを返して、新しいRequestsをSpider Middleware経由で送る
- スクレイプしたアイテムはItem Pipelinesへ送られ、crawlに対して次のRequestsを確認する
- Requestsがなくなるまで繰り返す
