Scrapyのクローラーでファイルをダウンロードして保存する
Scrapyでファイルをダウンロードして保存する
scrapyで複数ページを巡回はCrawlSpider、ファイルのダウンロードはFilesPipelineを使うと簡潔に記述できる。
FilesPipelineはデフォルトではSha1ハッシュをファイル名にする実装なので、カスタマイズが必要。
ソースコードは簡潔で読みやすいので継承してカスタマイズするのは容易。
CrawlSpider
要約すると、ポイントは以下
- 巡回対象のページを
rulesにLinkExtractorで抽出 - コールバックで抽出したページからアイテムを抽出
FilesPipeline
要約すると、ポイントは以下
- settings.pyの
FILES_STOREでFILES_STOREによるダウンロード先ディレクトリを指定 - settings.pyの
ITEM_PIPELINESでFilesPipelineを有効化 - 生成するアイテムに
file_urls属性を追加し、ダウンロードするファイルのURLsを指定 - 生成するアイテムにダウンロード結果を保存する
fiiles属性を追加する
Using the Files Pipeline
The typical workflow, when using the FilesPipeline goes like this:
In a Spider, you scrape an item and put the URLs of the desired into a file_urls field.
The item is returned from the spider and goes to the item pipeline.
When the item reaches the FilesPipeline, the URLs in the file_urls field are scheduled for download using the standard Scrapy scheduler and downloader (which means the scheduler and downloader middlewares are reused), but with a higher priority, processing them before other pages are scraped. The item remains “locked” at that particular pipeline stage until the files have finish downloading (or fail for some reason).
When the files are downloaded, another field (files) will be populated with the results. This field will contain a list of dicts with information about the downloaded files, such as the downloaded path, the original scraped url (taken from the file_urls field) , and the file checksum. The files in the list of the files field will retain the same order of the original file_urls field. If some file failed downloading, an error will be logged and the file won’t be present in the files field.
Spiderでスクレイピングし、目的のURLをfile_urlsにセットすると、SchedulerとDownloaderを使ってスケジューリングされるが、優先度が高く他のページをスクレイピングする前に処理される。ダウンロード結果はfilesに記録する。
Enabling your Media Pipeline
To enable your media pipeline you must first add it to your project ITEM_PIPELINES setting.
For Images Pipeline, use:
ITEM_PIPELINES = {‘scrapy.pipelines.images.ImagesPipeline’: 1}
For Files Pipeline, use:ITEM_PIPELINES = {‘scrapy.pipelines.files.FilesPipeline’: 1}
ITEM_PIPELINESでscrapy.pipelines.files.FilesPipeline': 1を指定して有効化する。
画像ファイルのためのImagesPipelineもある。
Supported Storage - File system storage
The files are stored using a SHA1 hash of their URLs for the file names.
ファイル名はSHA1ハッシュを使用する
IPAの情報処理試験のページをサンプルにCrawlSpiderを試す
対象のページ構造
起点となるページは各年度の過去問ダウンロードページへのリンクになっている。
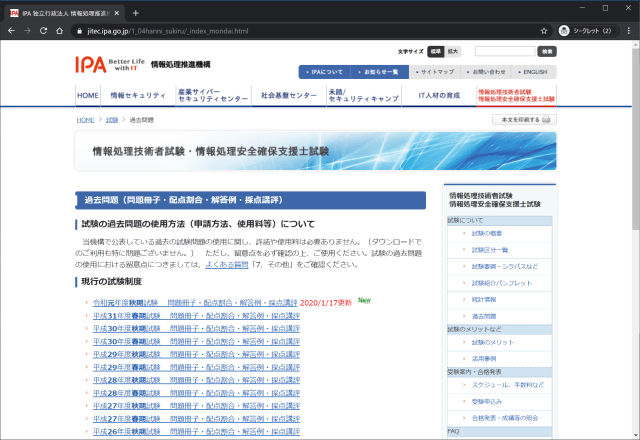
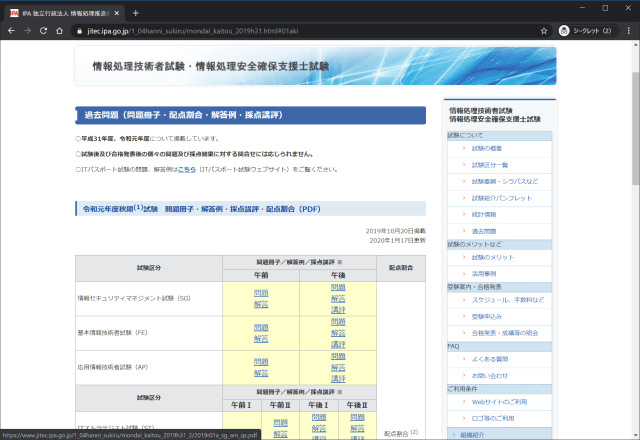
各ページは試験区分ごとに過去問のPDFへのリンクがある。
project
https://www.jitec.ipa.go.jp/1_04hanni_sukiru/_index_mondai.html以下のページを巡回してPDFをダウンロードするプロジェクトを作成する。
Spiderのスケルトンを作成する際に-t crawlを指定し、CrawlSpiderのスケルトンを作成する。
1 | scrapy startproject <プロジェクト名> |
spiders/ipa.py
rulesで各年度の過去問ダウンロードページを抽出し、各ページを解析してPDF単位でアイテム化する。file_urlsは複数指定できるが、ここでは1ファイル毎で指定している。
1 | # -*- coding: utf-8 -*- |
items.py
files_urlsとfiles属性がFilesPipelineで必要になる属性
1 | import scrapy |
pipelines.py
FilesPipelineはデフォルトでSHA1ハッシュのファイル名を使用するので、継承したクラスでfile_path()メソッドをオーバーライドする。
存在しないディレクトリも自動生成されるので、保存したいパスを生成して返せばいい。
1 | from scrapy.pipelines.files import FilesPipeline |
1 | response.url="https://www.jitec.ipa.go.jp/1_04hanni_sukiru/mondai_kaitou_2019h31_2/2019r01a_sg_am_qs.pdf" |
setting.py
FilesPipelineを有効化する。
FILES_STOREでダウンロード先ディレクトリを指定ITEM_PIPELINESでFilesPipelineを有効化
デフォルト設定では多重度が高すぎるので、調整する。
- 同時アクセスは1
- ダウンロード間隔3秒
1 | # Obey robots.txt rules |
