GitHub Actionsの実行結果を確認する
GitHubのWebUIで確認する
Actionsタブから実行結果を確認できる。
WebUIの画面で対象のワークフローを選択すると、過去の実行履歴が表示される。履歴を選択すると詳細を確認できる。

バッジで確認する
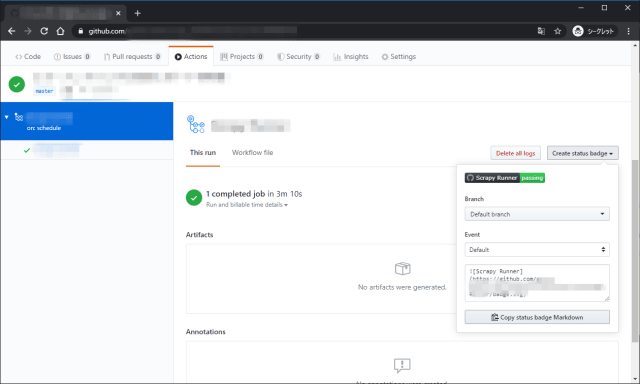
バッジで最終実行結果の状態を見ることができる。
Markdownが表示されるのでREADME.mdに貼っておけば、リポジトリのトップページで確認できる。
通常のログ
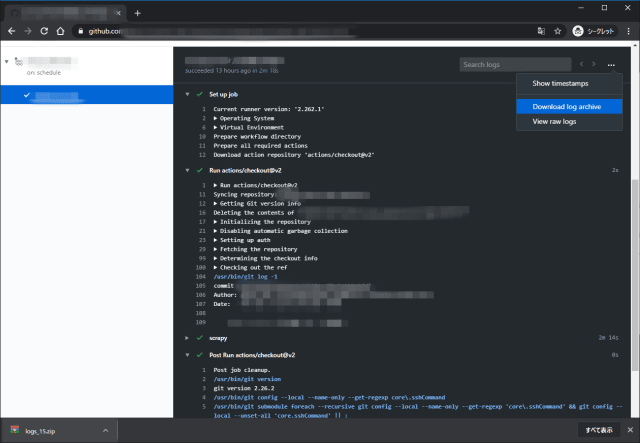
ワークフローのを選択すると詳細を確認できる。各ステップのログがそれぞれ表示され、ログの閲覧やダウンロードなどが可能。
生ログの閲覧。

ログのダウンロード。
GitHub Actionsのワークフローデバッグ
デバッグログを出力して実行の詳細を記録することができる。
Enabling debug logging
Runner diagnostic logging provides additional log files that contain information about how a runner is executing a job. Two extra log files are added to the log archive:
- The runner process log, which includes information about coordinating and setting up runners to execute jobs.
- The worker process log, which logs the execution of a job.
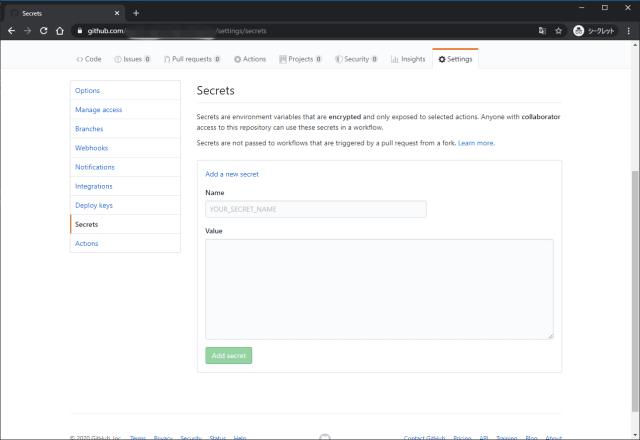
- To enable runner diagnostic logging, set the following secret in the repository that contains the workflow: ACTIONS_RUNNER_DEBUG to true.
- To download runner diagnostic logs, download the log archive of the workflow run. The runner diagnostic logs are contained in the runner-diagnostic-logs folder. For more information on downloading logs, see “Downloading logs.”
- secretで
ACTIONS_RUNNER_DEBUGをtrueで設定する。 - 作成されたログはダウンロードしたZIPファイル内の
runner-diagnostic-logsにある。
runner-diagnostic-logs内にはBuild UnknownBuildNumber-<リポジトリ名>.zipのアーカイブがあり、以下のファイルがある。
1 | Mode LastWriteTime Length Name |
Enabling step debug logging
Step debug logging increases the verbosity of a job’s logs during and after a job’s execution.
- To enable step debug logging, you must set the following secret in the repository that contains the workflow: ACTIONS_STEP_DEBUG to true.
- After setting the secret, more debug events are shown in the step logs. For more information, see “Viewing logs to diagnose failures”.
- secretで
ACTIONS_STEP_DEBUGをtrueで設定する。 - 設定後ステップログでデバッグイベントが出力される。
ログに[debug]の付いた行が追加されている。画面上ではパープルでハイライトされ、より詳細なステップログになっている。

1 | ##[debug]Starting: Complete job |