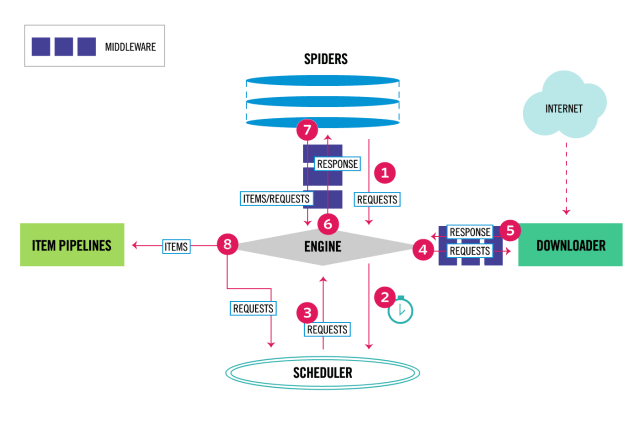
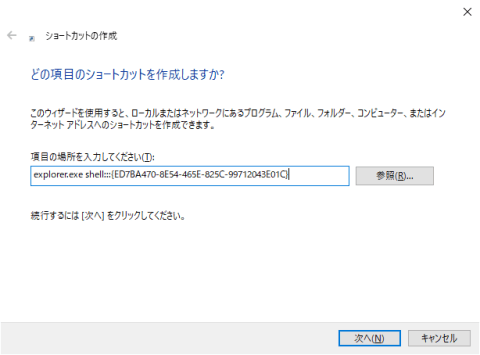
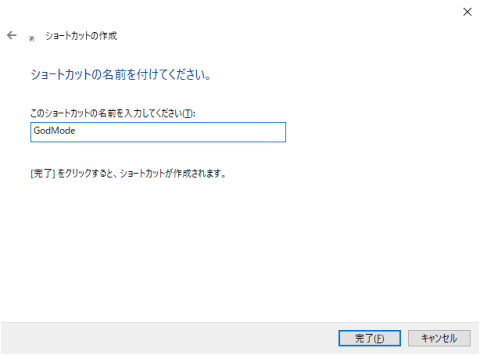
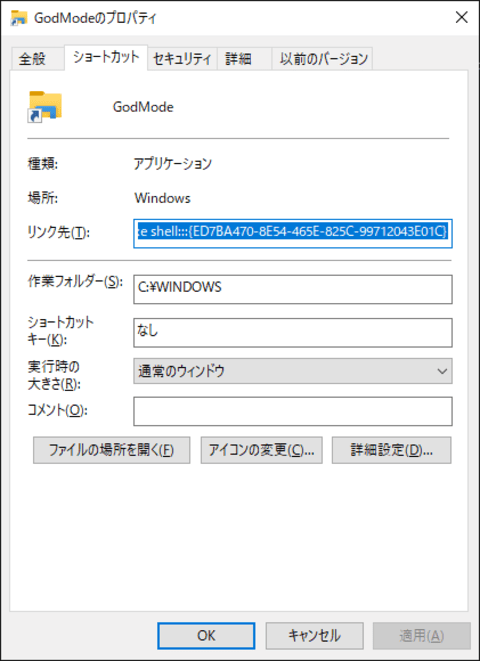
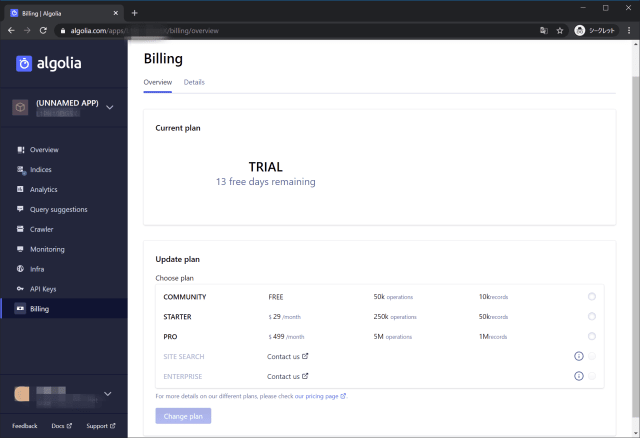
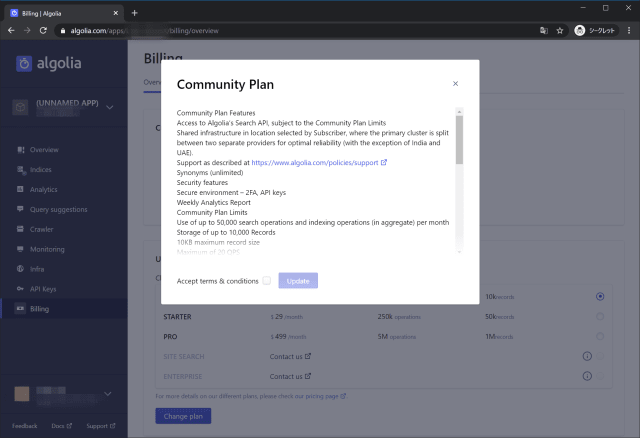
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
| import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes2"
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
`````````
実行結果。
``` python
$scrapy crawl quotes2
2020-05-03 02:05:13 [scrapy.utils.log] INFO: Scrapy 2.1.0 started (bot: scrapy_tutorial_quotes)
2020-05-03 02:05:13 [scrapy.utils.log] INFO: Versions: lxml 4.5.0.0, libxml2 2.9.10, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 20.3.0, Python 3.8.2 (default, Apr 16 2020, 18:36:10) - [GCC 8.3.0], pyOpenSSL 19.1.0 (OpenSSL 1.1.1g 21 Apr 2020), cryptography 2.9.2, Platform Linux-4.19.76-linuxkit-x86_64-with-glibc2.2.5
2020-05-03 02:05:13 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.epollreactor.EPollReactor
2020-05-03 02:05:13 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'scrapy_tutorial_quotes',
'EDITOR': '/usr/bin/vim',
'NEWSPIDER_MODULE': 'scrapy_tutorial_quotes.spiders',
'ROBOTSTXT_OBEY': True,
'SPIDER_MODULES': ['scrapy_tutorial_quotes.spiders']}
2020-05-03 02:05:13 [scrapy.extensions.telnet] INFO: Telnet Password: 6bee2d1ba39b9e9c
2020-05-03 02:05:13 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.logstats.LogStats']
2020-05-03 02:05:13 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2020-05-03 02:05:13 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2020-05-03 02:05:13 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2020-05-03 02:05:13 [scrapy.core.engine] INFO: Spider opened
2020-05-03 02:05:13 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2020-05-03 02:05:13 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2020-05-03 02:05:14 [scrapy.core.engine] DEBUG: Crawled (404) <GET http://quotes.toscrape.com/robots.txt> (referer: None)
2020-05-03 02:05:14 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/page/1/> (referer: None)
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/1/>
{'text': '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”', 'author': 'Albert Einstein', 'tags': ['change', 'deep-thoughts', 'thinking', 'world']}
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/1/>
{'text': '“It is our choices, Harry, that show what we truly are, far more than our abilities.”', 'author': 'J.K. Rowling', 'tags': ['abilities', 'choices']}
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/1/>
{'text': '“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”', 'author': 'Albert Einstein', 'tags': ['inspirational', 'life', 'live', 'miracle', 'miracles']}
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/1/>
{'text': '“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”', 'author': 'Jane Austen', 'tags': ['aliteracy', 'books', 'classic', 'humor']}
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/1/>
{'text': "“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”", 'author': 'Marilyn Monroe', 'tags': ['be-yourself', 'inspirational']}
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/1/>
{'text': '“Try not to become a man of success. Rather become a man of value.”', 'author': 'Albert Einstein', 'tags': ['adulthood', 'success', 'value']}
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/1/>
{'text': '“It is better to be hated for what you are than to be loved for what you are not.”', 'author': 'André Gide', 'tags': ['life', 'love']}
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/1/>
{'text': "“I have not failed. I've just found 10,000 ways that won't work.”", 'author': 'Thomas A. Edison', 'tags': ['edison', 'failure', 'inspirational', 'paraphrased']}
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/1/>
{'text': "“A woman is like a tea bag; you never know how strong it is until it's in hot water.”", 'author': 'Eleanor Roosevelt', 'tags': ['misattributed-eleanor-roosevelt']}
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/1/>
{'text': '“A day without sunshine is like, you know, night.”', 'author': 'Steve Martin', 'tags': ['humor', 'obvious', 'simile']}
2020-05-03 02:05:15 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/page/2/> (referer: None)
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/2/>
{'text': "“This life is what you make it. No matter what, you're going to mess up sometimes, it's a universal truth. But the good part is you get to decide how you're going to mess it up. Girls will be your friends - they'll act like it anyway. But just remember, some come, some go. The ones that stay with you through everything - they're your true best friends. Don't let go of them. Also remember, sisters make the best friends in the world. As for lovers, well, they'll come and go too. And baby, I hate to say it, most of them - actually pretty much all of them are going to break your heart, but you can't give up because if you give up, you'll never find your soulmate. You'll never find that half who makes you whole and that goes for everything. Just because you fail once, doesn't mean you're gonna fail at everything. Keep trying, hold on, and always, always, always believe in yourself, because if you don't, then who will, sweetie? So keep your head high, keep your chin up, and most importantly, keep smiling, because life's a beautiful thing and there's so much to smile about.”", 'author': 'Marilyn Monroe', 'tags': ['friends', 'heartbreak', 'inspirational', 'life', 'love', 'sisters']}
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/2/>
{'text': '“It takes a great deal of bravery to stand up to our enemies, but just as much to stand up to our friends.”', 'author': 'J.K. Rowling', 'tags': ['courage', 'friends']}
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/2/>
{'text': "“If you can't explain it to a six year old, you don't understand it yourself.”", 'author': 'Albert Einstein', 'tags': ['simplicity', 'understand']}
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/2/>
{'text': "“You may not be her first, her last, or her only. She loved before she may love again. But if she loves you now, what else matters? She's not perfect—you aren't either, and the two of you may never be perfect together but if she can make you laugh, cause you to think twice, and admit to being human and making mistakes, hold onto her and give her the most you can. She may not be thinking about you every second of the day, but she will give you a part of her that she knows you can break—her heart. So don't hurt her, don't change her, don't analyze and don't expect more than she can give. Smile when she makes you happy, let her know when she makes you mad, and miss her when she's not there.”", 'author': 'Bob Marley', 'tags': ['love']}
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/2/>
{'text': '“I like nonsense, it wakes up the brain cells. Fantasy is a necessary ingredient in living.”', 'author': 'Dr. Seuss', 'tags': ['fantasy']}
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/2/>
{'text': '“I may not have gone where I intended to go, but I think I have ended up where I needed to be.”', 'author': 'Douglas Adams', 'tags': ['life', 'navigation']}
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/2/>
{'text': "“The opposite of love is not hate, it's indifference. The opposite of art is not ugliness, it's indifference. The opposite of faith is not heresy, it's indifference. And the opposite of life is not death, it's indifference.”", 'author': 'Elie Wiesel', 'tags': ['activism', 'apathy', 'hate', 'indifference', 'inspirational', 'love', 'opposite', 'philosophy']}
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/2/>
{'text': '“It is not a lack of love, but a lack of friendship that makes unhappy marriages.”', 'author': 'Friedrich Nietzsche', 'tags': ['friendship', 'lack-of-friendship', 'lack-of-love', 'love', 'marriage', 'unhappy-marriage']}
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/2/>
{'text': '“Good friends, good books, and a sleepy conscience: this is the ideal life.”', 'author': 'Mark Twain', 'tags': ['books', 'contentment', 'friends', 'friendship', 'life']}
2020-05-03 02:05:15 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/2/>
{'text': '“Life is what happens to us while we are making other plans.”', 'author': 'Allen Saunders', 'tags': ['fate', 'life', 'misattributed-john-lennon', 'planning', 'plans']}
2020-05-03 02:05:15 [scrapy.core.engine] INFO: Closing spider (finished)
2020-05-03 02:05:15 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 681,
'downloader/request_count': 3,
'downloader/request_method_count/GET': 3,
'downloader/response_bytes': 6003,
'downloader/response_count': 3,
'downloader/response_status_count/200': 2,
'downloader/response_status_count/404': 1,
'elapsed_time_seconds': 1.762026,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2020, 5, 2, 17, 5, 15, 270853),
'item_scraped_count': 20,
'log_count/DEBUG': 23,
'log_count/INFO': 10,
'memusage/max': 55705600,
'memusage/startup': 55705600,
'response_received_count': 3,
'robotstxt/request_count': 1,
'robotstxt/response_count': 1,
'robotstxt/response_status_count/404': 1,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2020, 5, 2, 17, 5, 13, 508827)}
2020-05-03 02:05:15 [scrapy.core.engine] INFO: Spider closed (finished)
|