$python sample_test.py Traceback (most recent call last): File "/usr/local/lib/python3.8/site-packages/selenium/webdriver/common/service.py", line 72, in start self.process = subprocess.Popen(cmd, env=self.env, File "/usr/local/lib/python3.8/subprocess.py", line 854, in __init__ self._execute_child(args, executable, preexec_fn, close_fds, File "/usr/local/lib/python3.8/subprocess.py", line 1702, in _execute_child raise child_exception_type(errno_num, err_msg, err_filename) FileNotFoundError: [Errno 2] No such file or directory: 'chromedriver'
During handling of the above exception, another exception occurred:
Traceback (most recent call last): File "sample_test.py", line 13, in <module> driver = webdriver.Chrome(options=options) File "/usr/local/lib/python3.8/site-packages/selenium/webdriver/chrome/webdriver.py", line 73, in __init__ self.service.start() File "/usr/local/lib/python3.8/site-packages/selenium/webdriver/common/service.py", line 81, in start raise WebDriverException( selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/home
Kubernetes has well and truly cornered the domain of container orchestration, and is arguably becoming the default cloud-agnostic compute abstraction. However, Kubernetes is not a complete Platform-as-a-Service (PaaS), which is arguably what most organisations require for effective deployment and operation of software, and so the next “hot topics” in this space appear to be “service meshes” for managing interservice communication and release control, and developer experience and workflow tooling to allow engineers to implement effective dev-test-deploy-observe cycles.
We believe that the topic of chaos engineering has moved into early adopter, largely due to the increased promotion by the Netflix team and the O’Reilly Chaos Engineering book authors, and tooling such as the Chaos Toolkit and Gremlin’s as-a-service offerings. Based on discussions with John Allspaw, Casey Rosenthal, Nora Jones and other members of the community, we have separated out the topic of “resilience engineering”, which we have previously conflated with chaos engineering, and placed this within the innovator category.
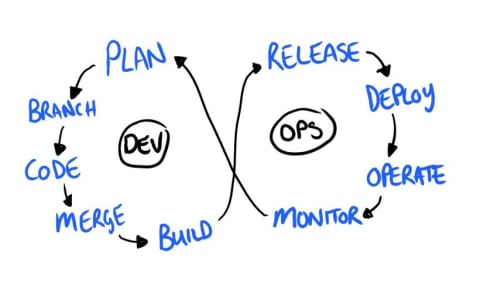
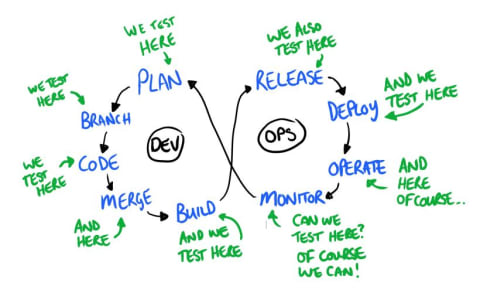
Put simply, shift left refers to the concept of performing a given process earlier in the software delivery chain. When you hear people talking about the shift-left concept today, they’re usually discussing either software testing or IT security. However, the shift-left idea can be applied to any type of process that occurs within the delivery chain. Data management, software monitoring and even software marketing could be moved to the left, too.
As you might imagine, shifting processes to the right means performing them later in the delivery pipeline. In many cases, this specifically means taking processes that typically happen before application release and moving them into production, to help you catch post-release issues before end users notice them.
テストやセキュリティなどのコアソフトウェア配信プロセスを継続実施することが重要。
Shift-left and shift-right are both valuable concepts, but DevOps teams should not embrace them in isolation. Instead, think of shift-left and shift-right as steps that you can take to make core software delivery processes like testing and security continuous across your pipeline. Continuity is the real goal.
I think the first time I heard the term was in a talk by Paul Gerrard – perhaps a webinar for EuroStar in 2014. In the notes I made at the time, I have this sentence “ Shift Left ??? – redistributing test activities … same thing we have been saying … why is he calling it shift left? I don’t understand this at all.”
What I fear may happen using the term ‘shift-left’, is that some people will misunderstand the concept and go back to big upfront requirements that need to be tested before coding is even started. Shift-left also doesn’t include the idea of DevOps, so people have started saying shift-right, or shift-outwards. I personally think better terms are testing continuously or holistic testing, taking into account whatever your context may be.
Shift-right entails doing more testing in the immediate pre-release and post-release phases (i.e. testing in production) of the application lifecycle. These include practices such as: release validation, destructive/chaos testing, A/B and canary testing, CX-based testing (e.g. correlating user behavior with test requirements), crowd testing, production monitoring, extraction of test insights from production data, etc. Shift-right not only introduces such new testing techniques, but also requires testers to acquire new skills, make aggressive use of production data to drive testing strategies and collaborate with new stakeholders, such as site reliability engineers (SRE) and operations engineers.
Unlike classic testing, this takes into account real-world users and their experiences. An application with perfect traditional quality scores (such as FURPS) may still suffer from poor CX if it fails to delight the customer. CX is measured using various metrics such as Customer Effort Score (CES), Net Promoter Score (NPS), Customer Satisfaction Score (CSAT), etc. While it is possible to shift-left some of these measurements to some degree, most CX measurements are deduced from systems in production (or close to production).
Though the term TestOps (like all the X-Ops sub-disciplines within DevOps) implies the collaboration between testing and operations, it isn’t simply about shift-right. Why? Because with DevOps, operational disciplines themselves have shifted left (such as shift-left of monitoring, configuration management, SRE, etc.). Hence TestOps—true to the principle of continuous testing—refers to better collaboration with operations disciplines across the DevOps lifecycle.
Compile your application code. Getting the latest version of any recent code changes from other developers is purely optional and not a requirement for certification.
Launch the application or website that has just been compiled.
Cause one code path in the code you’re checking in to be executed. The preferred way to do this is with ad-hoc manual testing of the simplest possible case for the feature in question. Omit this step if the code change was less than five lines, or if, in the developer’s professional opinion, the code change could not possibly result in an error.
Check the code changes into your version control system.