After an item has been scraped by a spider, it is sent to the Item Pipeline which processes it through several components that are executed sequentially.
Each item pipeline component (sometimes referred as just “Item Pipeline”) is a Python class that implements a simple method. They receive an item and perform an action over it, also deciding if the item should continue through the pipeline or be dropped and no longer processed.
SpiderでItemがスクレイプされた後、ItemPipelineに送られ、処理される。
Typical uses of item pipelines are:
cleansing HTML data
validating scraped data (checking that the items contain certain fields)
The integer values you assign to classes in this setting determine the order in which they run: items go through from lower valued to higher valued classes. It’s customary to define these numbers in the 0-1000 range.
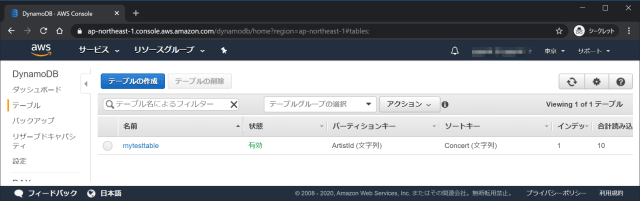
local secondary index は特定のパーティションキー値の代替ソートキーを維持します。また local secondary index には、ベーステーブルの一部またはすべての属性のコピーが含まれます。テーブルを作成する際に、local secondary index に射影する属性を指定します。local secondary indexのデータは、ベーステーブルと同じパーティションキーと、異なるソートキーで構成されます。これにより、この異なるディメンションにわたってデータ項目に効率的にアクセスできます。クエリまたはスキャンの柔軟性を向上するために、テーブルごとに最大 5 つのlocal secondary indexを作成できます。
テーブルとは異なるソートキーを持つインデックス。最大5個まで作成できる。
local secondary index は、すべて次の条件を満たす必要があります。 パーティションキーはそのベーステーブルのパーティションキーと同じである。 ソートキーは完全に 1 つのスカラー属性で構成されている。 ベーステーブルのソートキーがインデックスに射影され、非キー属性として機能する。
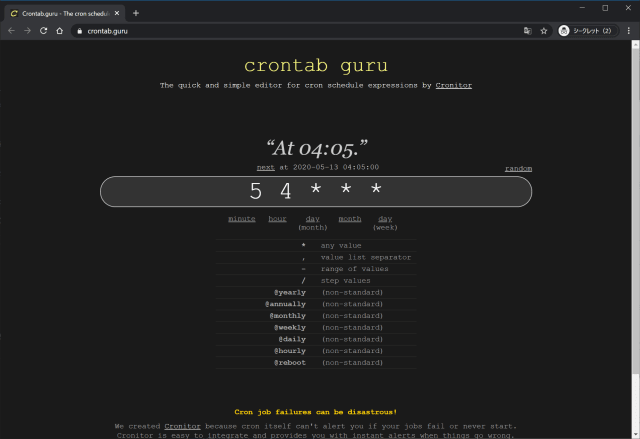
on: schedule: # At 02:00.(JST) → At 17:00.(UTC) -cron:'0 17 * * *'
# A workflow run is made up of one or more jobs that can run sequentially or in parallel jobs: # This workflow contains a single job called "build" build: # The type of runner that the job will run on runs-on:ubuntu-latest timeout-minutes:10
# This is a basic workflow to help you get started with Actions name:docker-compose
# Controls when the action will run. Triggers the workflow on push or pull request # events but only for the master branch on: push: branches: -master
# A workflow run is made up of one or more jobs that can run sequentially or in parallel jobs: # This workflow contains a single job called "build" build: # The type of runner that the job will run on runs-on:ubuntu-latest
# Steps represent a sequence of tasks that will be executed as part of the job steps: # Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it -uses:actions/checkout@v2
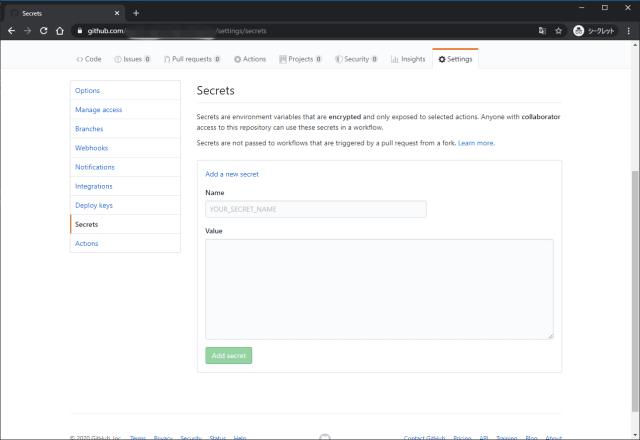
# Runs a single command using the runners shell -name:compose-run shell:bash env: ENVENV1:${{secrets.ENVENV1}} ENVENV2:${{secrets.ENVENV2}} run:| docker-compose up -d docker-compose exec -T app bash xxxxxxxx.sh
The typical workflow, when using the FilesPipeline goes like this:
In a Spider, you scrape an item and put the URLs of the desired into a file_urls field.
The item is returned from the spider and goes to the item pipeline.
When the item reaches the FilesPipeline, the URLs in the file_urls field are scheduled for download using the standard Scrapy scheduler and downloader (which means the scheduler and downloader middlewares are reused), but with a higher priority, processing them before other pages are scraped. The item remains “locked” at that particular pipeline stage until the files have finish downloading (or fail for some reason).
When the files are downloaded, another field (files) will be populated with the results. This field will contain a list of dicts with information about the downloaded files, such as the downloaded path, the original scraped url (taken from the file_urls field) , and the file checksum. The files in the list of the files field will retain the same order of the original file_urls field. If some file failed downloading, an error will be logged and the file won’t be present in the files field.
# Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 CONCURRENT_REQUESTS = 1
# Configure a delay for requests for the same website (default: 0) # See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 DOWNLOAD_DELAY = 3
Splash itself is stateless - each request starts from a clean state. In order to support sessions the following is required:
client (Scrapy) must send current cookies to Splash;
Splash script should make requests using these cookies and update them from HTTP response headers or JavaScript code;
updated cookies should be sent back to the client;
client should merge current cookies wiht the updated cookies.
For (2) and (3) Splash provides splash:get_cookies() and splash:init_cookies() methods which can be used in Splash Lua scripts.
Splashはステートレスなので、状態を維持するためのコーディングが必要。
ScrapyからSplashにCookieを送らなくてはならない
SplashスクリプトはCookieを使って操作し、Cookieをアップデートする
アップデートしたCookieをScrapyに返す
Scrapyは受け取ったCookieをマージする
scrapy-splash provides helpers for (1) and (4): to send current cookies in ‘cookies’ field and merge cookies back from ‘cookies’ response field set request.meta[‘splash’][‘session_id’] to the session identifier. If you only want a single session use the same session_id for all request; any value like ‘1’ or ‘foo’ is fine.
For scrapy-splash session handling to work you must use /execute endpoint and a Lua script which accepts ‘cookies’ argument and returns ‘cookies’ field in the result:
return { cookies = splash:get_cookies(), -- ... other results, e.g. html } end
SplashRequest sets session_id automatically for /execute endpoint, i.e. cookie handling is enabled by default if you use SplashRequest, /execute endpoint and a compatible Lua rendering script.
All these responses set response.url to the URL of the original request (i.e. to the URL of a website you want to render), not to the URL of the requested Splash endpoint. “True” URL is still available as response.real_url. plashJsonResponse provide extra features:
response.data attribute contains response data decoded from JSON; you can access it like response.data[‘html’].
If Splash session handling is configured, you can access current cookies as response.cookiejar; it is a CookieJar instance.
If Scrapy-Splash response magic is enabled in request (default), several response attributes (headers, body, url, status code) are set automatically from original response body:
response.headers are filled from ‘headers’ keys;
response.url is set to the value of ‘url’ key;
response.body is set to the value of ‘html’ key, or to base64-decoded value of ‘body’ key;
response.status is set from the value of ‘http_status’ key.
defparse_result(self, response): # here response.body contains result HTML; # response.headers are filled with headers from last # web page loaded to Splash; # cookies from all responses and from JavaScript are collected # and put into Set-Cookie response header, so that Scrapy # can remember them.